

Quando as pessoas se referem à inteligência artificial, alguns pensam nela como aprendizado de máquina , enquanto outros pensam nisso como aprendizado profundo ou aprendizado por reforço, etc. Embora inteligência artificial seja um termo amplo que envolve aprendizado de máquina , o aprendizado por reforço é um tipo de aprendizado de máquina, portanto, um ramo da IA . Neste artigo, entenderemos os 5 princípios-chave do aprendizado por reforço com alguns exemplos simples.
O aprendizado por reforço permite que máquinas e agentes de software determinem automaticamente o comportamento ideal dentro de um contexto específico, a fim de maximizar seu desempenho. Ele é empregado por vários softwares e máquinas para encontrar o melhor comportamento possível ou caminho que deve seguir em uma situação específica.
Este artigo é um trecho do livro AI Crash Course escrito por Hadelin de Ponteves. Neste livro, Hadelin o ajuda a entender o que você realmente precisa para construir sistemas de IA com aprendizado por reforço. O livro envolve projetos descritivos e práticos para colocar ideias em ação e mostrar como construir um software inteligente passo a passo.
Embora o aprendizado por reforço seja de alguma forma uma forma de IA, o aprendizado de máquina não inclui o processo de ação e interação com um ambiente como nós, humanos, fazemos. Na verdade, como seres humanos inteligentes, o que constantemente fazemos é o seguinte:
- Observamos alguma entrada, seja o que vemos com nossos olhos, o que ouvimos com nossos ouvidos ou o que lembramos em nossa memória.
- Essas entradas são então processadas em nosso cérebro.
- Eventualmente, tomamos decisões e agimos.
Esse processo de interação com um ambiente é o que estamos tentando reproduzir em termos de inteligência artificial. E, nessa medida, o ramo da IA que funciona nisso é o aprendizado por reforço. Esta é a combinação mais próxima de como pensamos; a forma mais avançada de inteligência artificial, se virmos a IA como a ciência que tenta imitar (ou superar) a inteligência humana.
Os princípios de aprendizagem por reforço também apresentam os resultados mais impressionantes em aplicações de negócios de IA. Por exemplo, o Alibaba aproveitou o aprendizado por reforço para aumentar seu ROI em publicidade online em 240%, sem aumentar seu orçamento de publicidade.

Cinco princípios de aprendizagem por reforço
Vamos começar a construir os primeiros pilares de sua intuição sobre como funciona o aprendizado por reforço. Esses são os princípios fundamentais de aprendizado por reforço, que o ajudarão a começar com os fundamentos sólidos e corretos de IA.
Aqui estão os cinco princípios:
- Princípio # 1: O sistema de entrada e saída
- Princípio 2: A recompensa
- Princípio # 3: O ambiente de IA
- Princípio 4: O processo de decisão de Markov
- Princípio # 5: Treinamento e inferência
Princípio # 1 – O sistema de entrada e saída
O primeiro passo é entender que hoje, todos os modelos de IA são baseados no princípio comum de entrada e saída. Cada forma de inteligência artificial, incluindo modelos de aprendizado de máquina, chatBots, sistemas de recomendação, robôs e, claro, modelos de aprendizado por reforço, receberá algo como entrada e retornará outra coisa como saída.
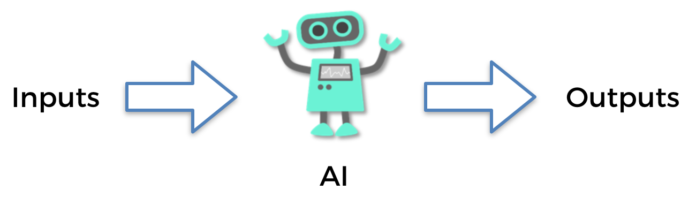
Figura 1: O sistema de entrada e saída
Na aprendizagem por reforço, esta entrada e saída têm um nome específico: a entrada é chamada de estado, ou estado de entrada. A saída é a ação realizada pelo AI. E no meio, não temos nada além de uma função que assume um estado como entrada e retorna uma ação como saída. Essa função é chamada de política. Lembre-se do nome, “política”, porque você o verá com frequência na literatura de IA.
Como exemplo, considere um carro que dirige sozinho. Tente imaginar qual seria a entrada e a saída nesse caso.
A entrada seria o que o sistema de visão computacional embutido vê, e a saída seria o próximo movimento do carro: acelerar, desacelerar, virar à esquerda, virar à direita ou frear. Observe que a saída a qualquer momento ( t ) pode muito bem ser várias ações realizadas ao mesmo tempo. Por exemplo, o carro que dirige sozinho pode acelerar enquanto ao mesmo tempo vira à esquerda. Da mesma forma, a entrada em cada tempo ( t ) pode ser composta por vários elementos: principalmente a imagem observada pelo sistema de visão computacional, mas também alguns parâmetros do carro como a velocidade da corrente, a quantidade de gás remanescente no tanque, e assim por diante.
Esse é o primeiro princípio importante da inteligência artificial: é um sistema inteligente (uma política) que recebe alguns elementos como entrada, faz sua mágica no meio e retorna algumas ações para executar como saída. Lembre-se de que as entradas também são chamadas de estados .
Princípio 2 – A recompensa
Cada IA tem seu desempenho medido por um sistema de recompensa. Não há nada de confuso nisso; a recompensa é simplesmente uma métrica que dirá à IA se ela se saiu bem ao longo do tempo.
O exemplo mais simples é uma recompensa binária: 0 ou 1. Imagine um AI que tem que adivinhar um resultado. Se a estimativa estiver certa, a recompensa será 1, e se a estimativa estiver errada, a recompensa será 0. Este poderia muito bem ser o sistema de recompensa definido para uma IA; realmente pode ser tão simples quanto isso!
Uma recompensa não precisa ser binária, no entanto. Pode ser contínuo. Considere o famoso jogo Breakout :
Figura 2: o jogo Breakout
Imagine um AI jogando este jogo. Tente descobrir qual seria a recompensa nesse caso. Pode ser simplesmente a pontuação; mais precisamente, a pontuação seria a recompensa acumulada ao longo do tempo em um jogo, e as recompensas poderiam ser definidas como o derivado dessa pontuação.
Esta é uma das muitas maneiras de definir um sistema de recompensa para esse jogo. Diferentes IAs terão diferentes estruturas de recompensa; construiremos cinco sistemas de recompensas para cinco aplicativos diferentes do mundo real neste livro.
Com isso em mente, lembre-se também: o objetivo final da IA sempre será maximizar a recompensa acumulada ao longo do tempo.
Esses são os dois primeiros princípios básicos, mas fundamentais, da inteligência artificial tal como existe hoje; o sistema de entrada e saída e a recompensa.
Princípio # 3 – ambiente de IA
O terceiro princípio de aprendizagem por reforço envolve um “ambiente de IA”. É uma estrutura muito simples, onde você definirá três coisas a cada vez ( t ):
- A entrada (o estado)
- A saída (a ação)
- A recompensa (a métrica de desempenho)
Para cada IA baseada na aprendizagem por reforço que é construída hoje, sempre definimos um ambiente composto pelos elementos anteriores. É, no entanto, importante entender que existem mais do que esses três elementos em um determinado ambiente de IA.
Por exemplo, se você estiver construindo uma IA para vencer um jogo de corrida de carros, o ambiente também conterá o mapa e a jogabilidade desse jogo. Ou, no exemplo de um carro que dirige sozinho, o ambiente também conterá todas as estradas ao longo das quais a IA está dirigindo e os objetos que circundam essas estradas. Mas o que você sempre encontrará em comum ao construir qualquer IA são os três elementos de estado, ação e recompensa.
Princípio nº 4 – O processo de decisão de Markov
O processo de decisão Markov, ou MDP, é simplesmente um processo que modela como a IA interage com o ambiente ao longo do tempo. O processo começa em t = 0 e, em seguida, a cada iteração seguinte, ou seja, t = 1, t = 2, … t = n unidades de tempo (onde a unidade pode ser qualquer coisa, por exemplo, 1 segundo), o AI segue o mesmo formato de transição:
- O AI observa o estado atual, s t
- A IA executa a ação, a t
- O AI recebe a recompensa, r t = R (s t , a t )
- O AI entra no seguinte estado, s t + 1
- O objetivo da IA é sempre o mesmo na aprendizagem por reforço: é maximizar as recompensas acumuladas ao longo do tempo, ou seja, a soma de todos os r t = R (s t , a t ) recebidos em cada transição. recebido em cada transição.
O gráfico a seguir o ajudará a visualizar e lembrar melhor um MDP, a base dos modelos de aprendizagem por reforço:
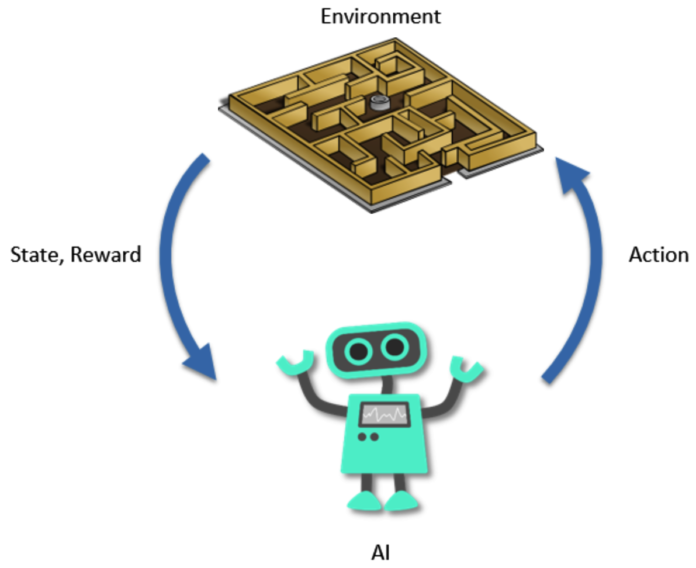
Figura 3: O processo de decisão de Markov
Agora, quatro pilares essenciais já estão moldando sua intuição de IA. Adicionar um último e importante completa a base de sua compreensão da IA. O último princípio é treinamento e inferência; no treinamento, a IA aprende e, na inferência, prevê.
Princípio # 5 – Treinamento e inferência
O princípio final que você deve entender é a diferença entre treinamento e inferência. Ao construir uma IA, há um tempo para o modo de treinamento e um tempo separado para o modo de inferência. Vou explicar o que isso significa começando com o modo de treinamento.
Modo de treinamento
Agora você entende, a partir dos três primeiros princípios, que a primeira etapa da construção de uma IA é construir um ambiente no qual os estados de entrada, as ações de saída e um sistema de recompensas sejam claramente definidos. A partir do quarto princípio, você também entende que dentro desse ambiente será construída uma IA que interage com ela, tentando maximizar a recompensa total acumulada ao longo do tempo.
Para simplificar, haverá um período preliminar (e longo) durante o qual a IA será treinada para fazer isso. Esse período é chamado de treinamento; também podemos dizer que o AI está em modo de treinamento. Durante esse tempo, a IA tenta realizar um determinado objetivo repetidamente até ter sucesso. Após cada tentativa, os parâmetros do modelo de IA são modificados para melhor desempenho na próxima tentativa.
Modo de inferência
O modo de inferência simplesmente surge depois que sua IA está totalmente treinada e pronta para um bom desempenho. Ele simplesmente consistirá em interagir com o ambiente executando as ações para cumprir a meta para a qual a IA foi treinada antes no modo de treinamento. No modo de inferência, nenhum parâmetro é modificado ao final de cada episódio.
Por exemplo, imagine que você tem uma empresa de IA que desenvolve soluções de IA personalizadas para empresas e um de seus clientes pediu que você construísse uma IA para otimizar os fluxos em uma rede inteligente. Primeiro, você entraria em uma fase de P&D durante a qual treinaria sua IA para otimizar esses fluxos (modo de treinamento) e, assim que atingir um bom nível de desempenho, entregaria sua IA ao seu cliente e entraria em produção . Sua IA regularia os fluxos na rede elétrica inteligente apenas observando os estados atuais da rede e realizando as ações para as quais foi treinada. Esse é o modo de inferência.
Às vezes, o ambiente está sujeito a mudanças; nesse caso, você deve alternar rapidamente entre os modos de treinamento e inferência para que sua IA possa se adaptar às novas mudanças no ambiente. Uma solução ainda melhor é treinar seu modelo de IA todos os dias e entrar no modo de inferência com o modelo treinado mais recentemente. Esse foi o último princípio fundamental comum a toda IA.
Aprendizado por reforço
Para resumir, exploramos os cinco princípios-chave de aprendizagem por reforço que envolvem o sistema de entrada e saída, um sistema de recompensa, ambiente de IA, processo de decisão de Markov, treinamento e modo de inferência para IA.
Materia traduzida do Inglês de site Packt





Sem comentários! Seja o primeiro.